Data management in various areas of everyday life is one of the important trends of the coming years. Big data is expected to reach $68 billion by 2025.
The key to working effectively with large data volumes is the competent use of Big Data services and a well-thought-out architecture. Let’s talk about what it should be like.
Big Data: What Is It?
First, let’s take a look at what big data is and why working with it is singled out as a separate layer of services. The generally accepted approach refers to big data as a process that consists of transferring, storing and analyzing large amounts of data.
More than large, in fact – we are talking terabytes and petabytes of information. With this scale, the usual data processing technologies may be ineffective. Ultimately, this affects the effectiveness of their further use.
The use of big data technologies makes it possible not only to store and process information on a large scale. You can also use it to:
- Logically structure large amounts of data;
- Speed up data processing without the risk of losing its value;
- Increase the computing power of software.
Big data is also needed to make information more open and accessible. Today, these technologies are successfully used to establish client-oriented services, improve the efficiency of business processes and predict possible risks.
What Does Big Data Structure Look Like?
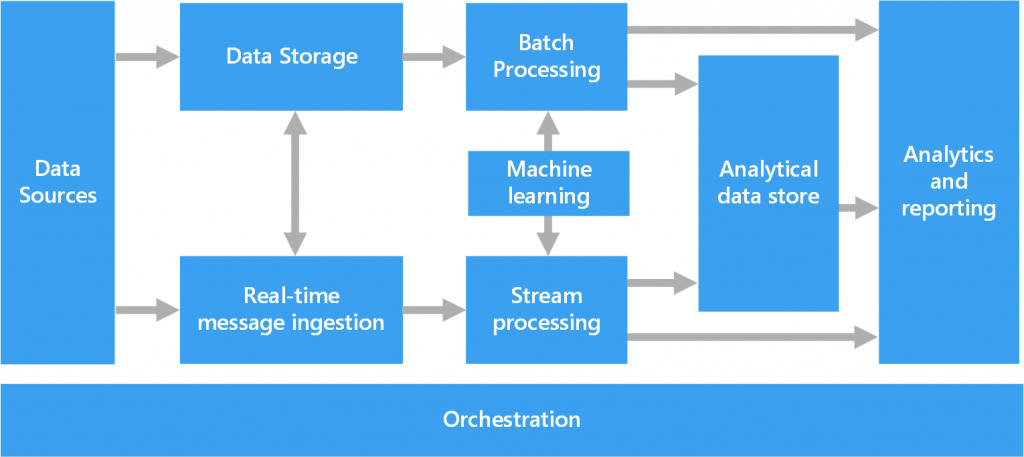
Despite the fact that big data technology is an integral process, several levels can be distinguished in it:
- Sources. These are devices, databases, programs, applications that provide file data. At this level, it is necessary not only to establish the operation of sources, but also to ensure uninterrupted transmission of information, even of large volumes.
- Control. At this level, the resulting files are converted into the format required for storage. The key requirement is the use of security protocols to ensure the safety of the information that they contain.
- Storage. Here, the converted data goes to the cloud storage system, which also provides access to the data.
- Analysis and use. Most often, business intelligence tools are used at this level to extract the necessary information.
It should be noted that there is no single standard for deploying big data architecture – it all depends on the scale and purposes it will be used for.
How Do You Build a Big Data Architecture?
The advantage of big data technologies is their flexibility, which makes it possible to scale services for their development according to business needs. Building a big data structure consists of several steps:
- Analysis of the needs for which it will be used;
- Audit of the data sources involved;
- Creation of a unified data management system (ETL);
- Implementation of API services for working with data;
- Development of a functional interface for users.
Each stage requires a thorough analysis of the needs for which the big data architecture is being developed. It is also necessary to check and test all solutions that are implemented in the system.
Things to Keep in Mind When Implementing Big Data Architecture
Like any technology, working with big data has its own specifics that should not be overlooked. When implementing big data architecture, you can face certain challenges:
- Insufficient level of data security, which makes them vulnerable to cyberattacks;
- Decrease in the quality of data and its information value;
- Lack of flexibility to scale to individual business requirements.
Despite this, the benefits of big data are still more obvious. Thanks to it, you can optimize the costs of storing and using data, as well as respond to unforeseen situations faster.