In today’s world, artificial intelligence (AI) is seen as a double-edged sword. On one side, there is the aspect of having smarter homes, improved health technology, and the prospect of having driverless vans to deliver groceries.
On the other side, there is the issue of privacy violations, discrimination and diverse effects of technologies in a negative way that is not yet discovered.
Various risks are involved in AI-related to data difficulties, comprising of ingesting high-quality data before the process of sorting, linking, and programming even takes place. In this article, 15 sources of machine learning datasets will be analysed.
1) Google Open Images
The Google Open Images is mainly a dataset that comprises of ~9 million URLs to images that have been interpreted with labels spread out over 6000 categories.
The people at Google ensure that they make the datasets as practical as possible which means that labels cover more real-life entities than the 1000 ImageNet classes.
The image-level annotations have been populated automatically through a vision model similar to the Google Cloud Vision API. The dataset is mainly a product of a collaboration between Google, CMU, and Cornell universities.
Here is the link to Google Open Images Dataset
2) ImageNet
The ImageNet is an image dataset that is organized according to the WorldNet hierarchy. The meaningful concept in WorldNet is mainly described through the use of multiple words or word phrases which is known as a “synonym set” or “synset”.
Within WorldNet, there are more than 100,000 synsets, most of them being nouns (80,000+). The images of each concept are quality controlled and human-annotated.
Here is the link to ImageNet Dataset.
Also Read: Top 6 Regression Algorithms Every Machine Learning Enthusiast Must Know
3) Waymo Open Dataset

The Waymo Open Dataset includes high-resolution sensor data which is collected by Waymo self-driving cars in a varied diversity of conditions.
This dataset mainly comprises lidar and camera data from around 1000 segments of the 20s each of which is gathered at 10Hz in different geographies and conditions.
Their sensor data is mainly 1 mid-range lidar, 4 short-range lidars, 5 cameras, synchronized lidar and camera data, lidar to camera projections, and sensor calibrations and vehicle pose. The labelled data has 4 object classes, high-quality labels for lidar data in each segment, and 12M 3D bounding box labels.
Here is the Github link to Waymo Open Dataset
4) UCI Machine Learning Repository
The UCI is a repository of 100s of datasets from the University of California, School of Information and Computer Science. This particular repository categorizes datasets through the type of machine learning problem.
Users would be able to discover datasets for univariate and multivariate time-series datasets, classification, regression or recommendation systems.
Here is the Github link to UCI Machine Learning Repository
5) Xview
Xview is considered to be one of the largest publicly available datasets of overhead imagery. It comprises images taken from complex scenes from all over the world, annotated using the bounding boxes.
The DIUxxView 2018 Detection Challenge is focused on accelerating progress in four areas of computer vision frontiers which are reducing minimum resolution for detection, improving the learning efficiency, enabling the discovery of more object classes, and improving detection of fine-grained classes.
Here is the Github link to Xview Dataset
6) MS COCO

COCO huge-scale object detection, segmentation, and captioning dataset. There are numerous features of this dataset which are object segmentation, 80 object categories, recognition in context, 5 captions per image, among many others.
Here is the Github link to MS COCO Dataset.
Also Read: Top 10 Best Python IDES and Code Editors
7) Visual Genome
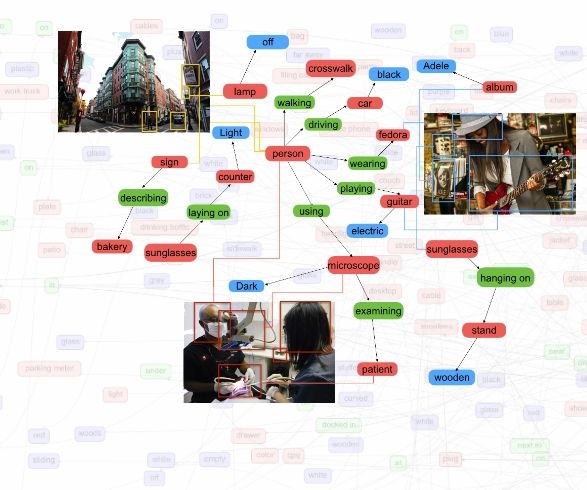
The visual genome is a dataset or a knowledge base that comprises of ongoing effort to connect with structured image concepts to language.
Here is the Github link to Visual Genome Dataset
8) Indoor Scene Recognition

The indoor scene recognition is seen as a difficult open problem having a high-level vision. Many scene recognition models tend to work efficiently for any kind of outdoor scenes that perform poorly in the indoor domain.
The major difficult area arises when some indoor scenes are efficiently characterized by global spatial properties, while others are comprised of objects that they contain.
The database comprises of 67 indoor categories and a total of 15620 images. The images are categorized into various aspects, with 100 images per category. The images are usually in jpeg format.
Here is the Github link to Indoor Scene Recognition Dataset
9) Labelme

This is a large dataset comprising of annotated images. This dataset works in two ways. The first one by downloading the images through LabelMe Matlab toolbox.
The toolbox allows the user to focus on that portion of the database that the individual wants to download. The second approach is through the use of images online with the help of the LabelMeMatlab toolbox.
Out of the two options, the first one is more preferred as the second option tends to be slower and can be time-taking.
After the installation of the database, the LabelMe Matlab toolbox helps to read the annotation files and query the images to extract specific objects.
Here is the link to Labelme Dataset.
Also Read: Keras vs TensorFlow – Know the Difference
10) Sentiment140
This is a popular dataset, which comprises 160,000 tweets ensuring the emoticons are removed from before. To collect and annotate the data, the approach sued in this dataset it unique owing to training data that is automatically created.
The process of automatically assuming tweets with positive emoticons like “:)” and tweets with negative emoticons like “:( “are considered. The datasets make use of the Twitter Search API to collect the tweets through the use of keyword searches.
Here is the link to Sentiment140 Dataset
11) Kaggle
This dataset includes a small community where different discussion about data, public code or creating own projects in Kernels is made part of.
There are various amounts of real-life datasets of different shapes and sizes in different formats available. The user can also make use of “kernels” to link with each dataset in numerous different data scientists that have provided notebooks to analyse the dataset.
12) Amazon Datasets
The amazon source comprises of various datasets in diverse fields, for instance, public transport, ecological resources, satellite images, and so on).
The source has a search box that assists in finding the dataset that the user is looking for. Moreover, there is also the dataset description and usage examples available for datasets that are considered to be informative and easy to make use of as well.
Here is the link to Amazon Datasets
13) Computer Vision Datasets
To understand the image processing in the best way, the computer vision or deep learning is seen as the source of data for carrying out such kind of experiments.
The Visual Data comprises of a handful number of diverse datasets that can be utilized to create computer vision (CV) models.
In this particular dataset, the user has the option to look for specific CV subject, which can be semantic segmentation, image captioning, image generation, as well as for opting for self-driving cars datasets.
Here is the link to Computer Vision Datasets
14) The MNIST dataset
This dataset is mainly about the database of handwritten digits. It includes a training set of 60,000 examples and a test set of 10,000 examples. This is mainly a subset of a larger set that is made available from NIST.
Here is the link to the MNIST dataset.
Also Read: 20 Must-Follow YouTube Channels to learn AI
15) The Chars74K dataset
Character recognition is a classic pattern recognition problem for which researchers have been working towards from the initial days of computer vision.
In today’s omnipresence of cameras, the applications of automatic character recognition are broader than they were before.
Some people prefer to call it the “English” characters set. The dataset usually comprises of:
- 64 classes (0-9, A-Z, a-z)
- 7705 characters attain through the natural images
- 3410 hand-drawn characters are made use of through the use of a tablet PC
- 62992 synthesized characters can be used from the computer fonts.
This is a total of more than 74K images, which is how the name of the dataset was created.
Here is the link to The Chars74K dataset
2 comments
I am so happy with the services I was provided with this website. The support team was awesome in explaining all the questions and concerns I had… My writer and support team get a rating of ten from me!!
Thank you for your collection of sources. I am going to study machine learning. I hope they will be helpful for me.